Protein Databases
Many public databases are available with information on proteins. Many datasets are aggregates of other datasets and therefore overlap between databases can be high. While some datasets are extensively curated by hand, most are automated and therefore redundancy within a dataset can also be high.
UniProt
Find a cytokine
| Protein name | UniProt | Sequence | PDB |
|---|---|---|---|
| Cytokine receptor-like factor 3 | Q8IUI8 | MRGAME ... 442 | - |
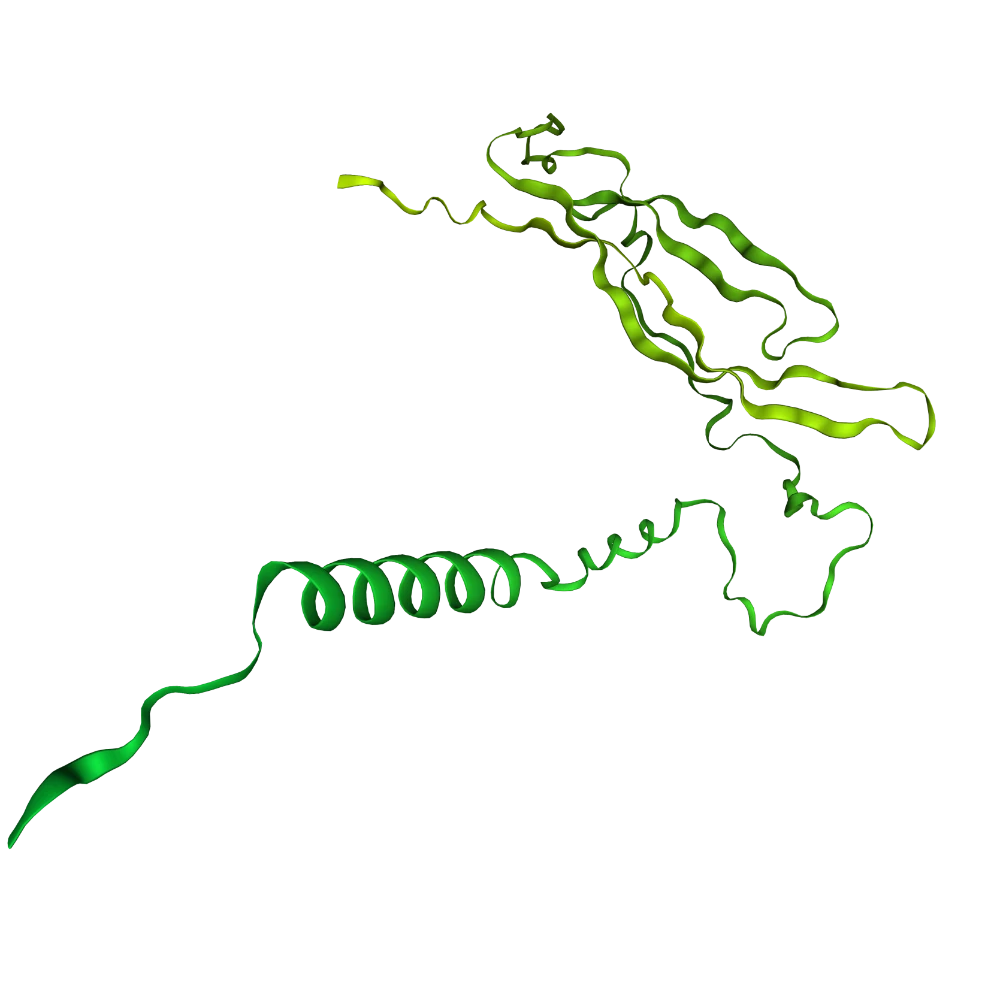
Find human hemoglobin
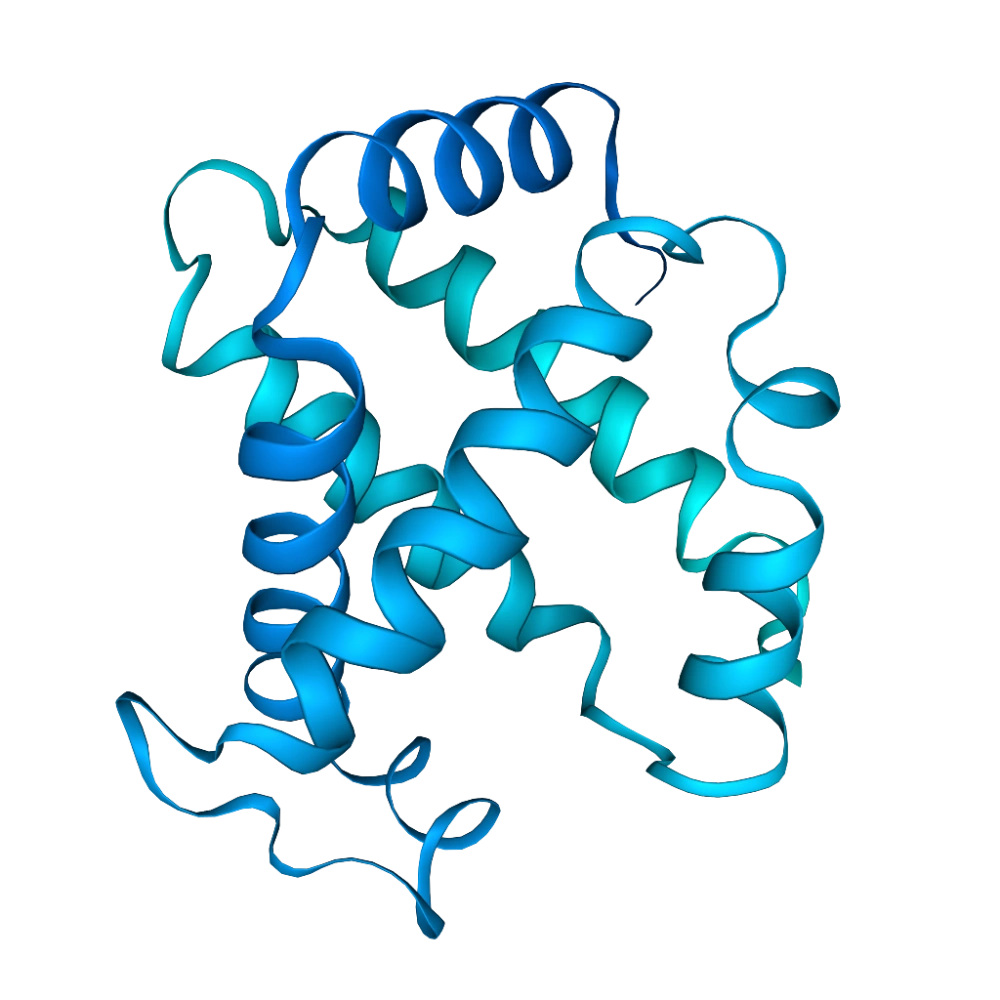
Load Q9HBE4
UniProt is a comprehensive protein sequence and functional information database, widely used by the scientific community. The data consists of manual and automated curation, experimental and predicted information.
- Num Rows: 231 M
- Size: 380 GB
- Identifier: UniProtID e.g. P01308, I7CLV3, A0A2K5R3V4
Protein Data Bank (PDB)
Fetch 1yvn
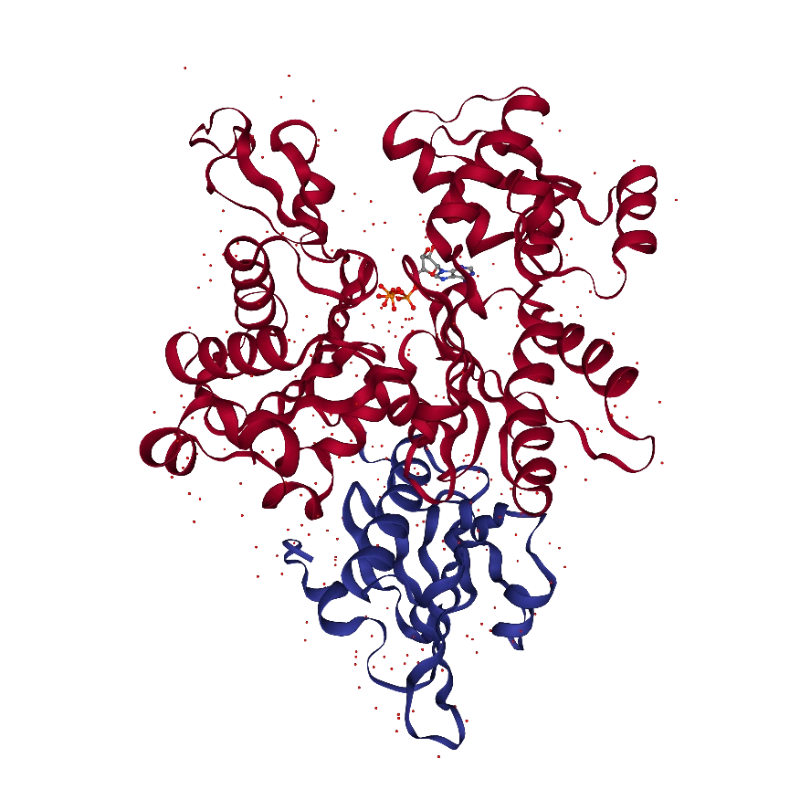
Load 6NX2
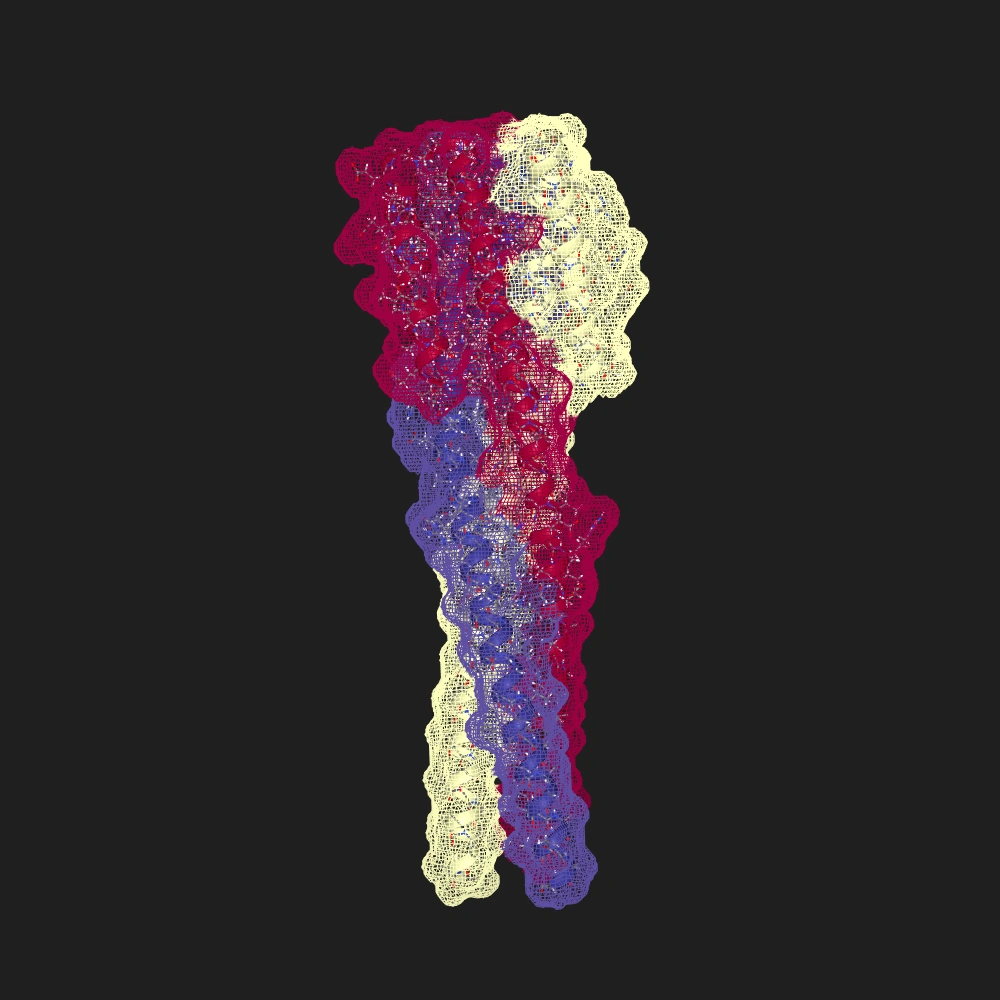
The Protein Data Bank (PDB) is a repository for experimental 3D structural data of biological molecules. The main focus is proteins, but includes nucleic acids, lipids, and small molecules. Experiments include crystallography, cryo-EM, NMR, and some other (e.g. SAXS). Data is manually entered by individual researchers.
- Num Rows: 218 K
- Size: 235 GB
- Identifier: PDB ID e.g. 6NX2, 6O0I, 6N9H
AlphaFold Database
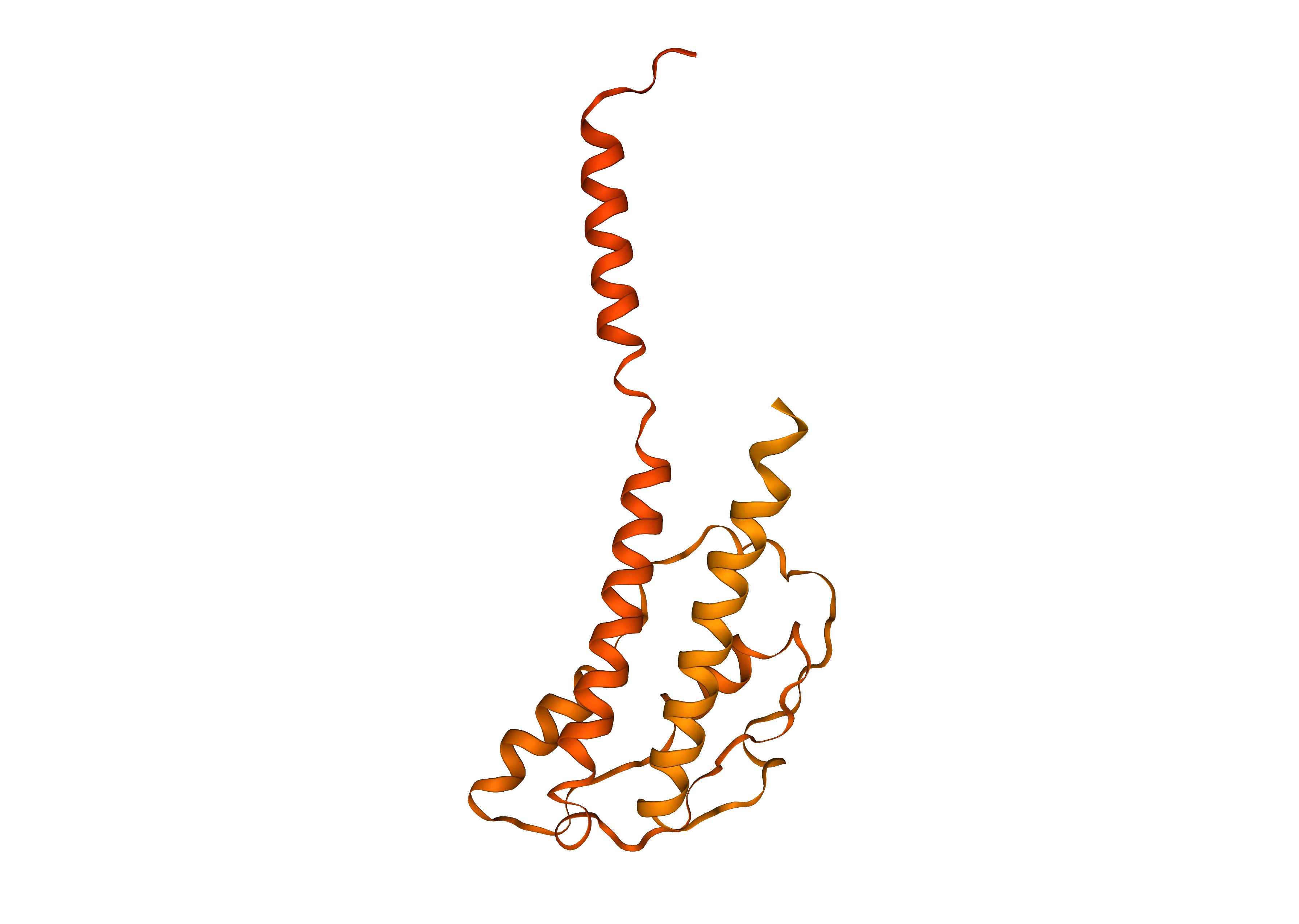
Find H2NHM8
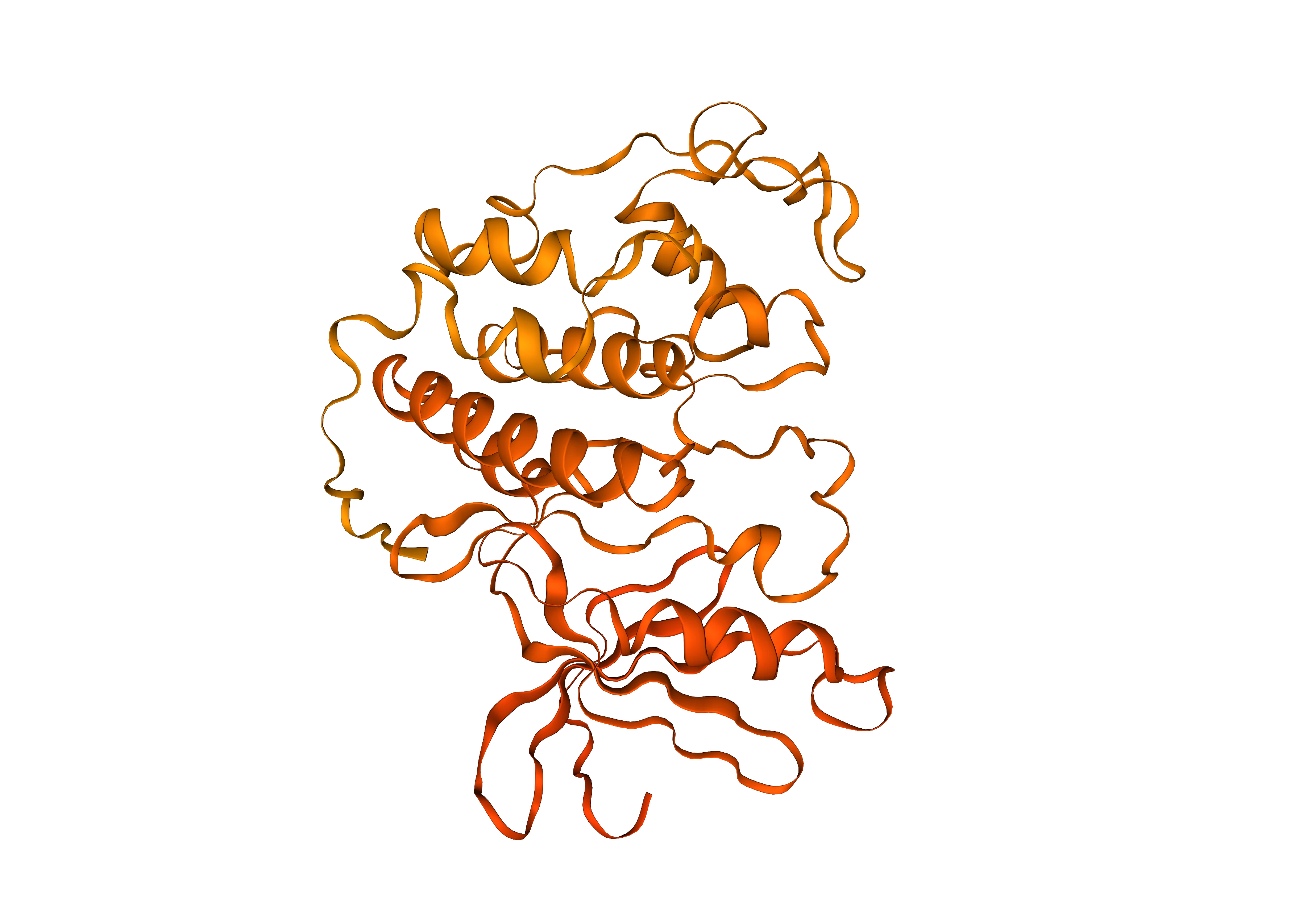
The AlphaFold Database provides AI-predicted 3D structures of proteins, covering natural protein sequences, and providing structures for those that do no have experimental structural data. Data is generated and quality-controlled automatically.
- Num Rows: 214 M
- Size: 23 TB
- Identifier: Based on UniProtID e.g. H2NHM8 is AF-H2NHM8-F1